
Introduction to GitOps
So You want to know about GitOps? Let's get Started with this blog. An easy to understand Tutorial with examples for GitOps.


Hey 🙋♂️, Welcome back, Today we will discuss about GitOps, so without wasting any time Let's get started.
What is GitOps?
At a very high level, you can think of GitOps as an iteration of DevOps that is centered around source code management.
And for most developers source control means using Git. It's pretty much the de facto standard. So let's start with this idea that DevOps is the foundation of GitOps.
DevOps is a mixture of principles, practices, and tools that allow teams to deliver higher quality software at a faster pace.
DevOps starts with culture. Teams embrace principles like breaking down silos, continuous improvement, automation, and frequent communication that improve how they deliver software.
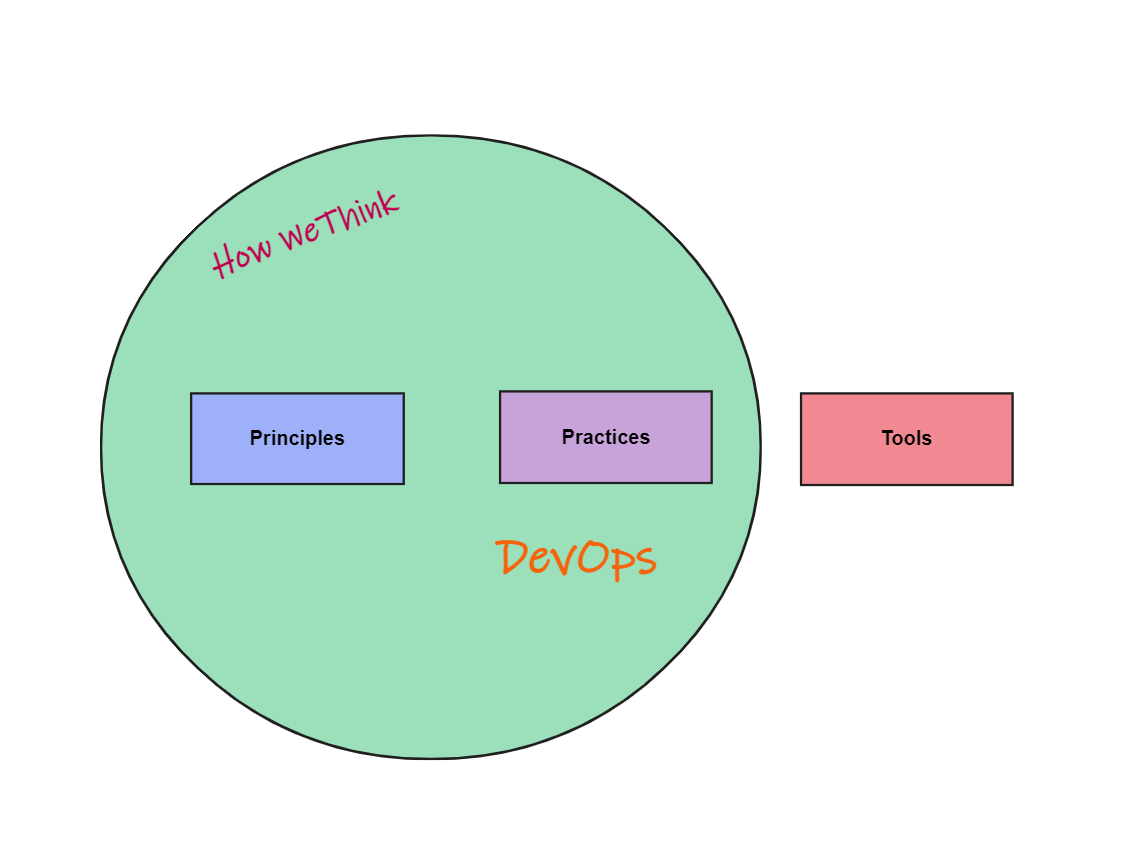
These principles change the way people in an organization think about developing and operating digital products. This influences how they work, and they adopt practices that rapidly deliver small incremental changes.
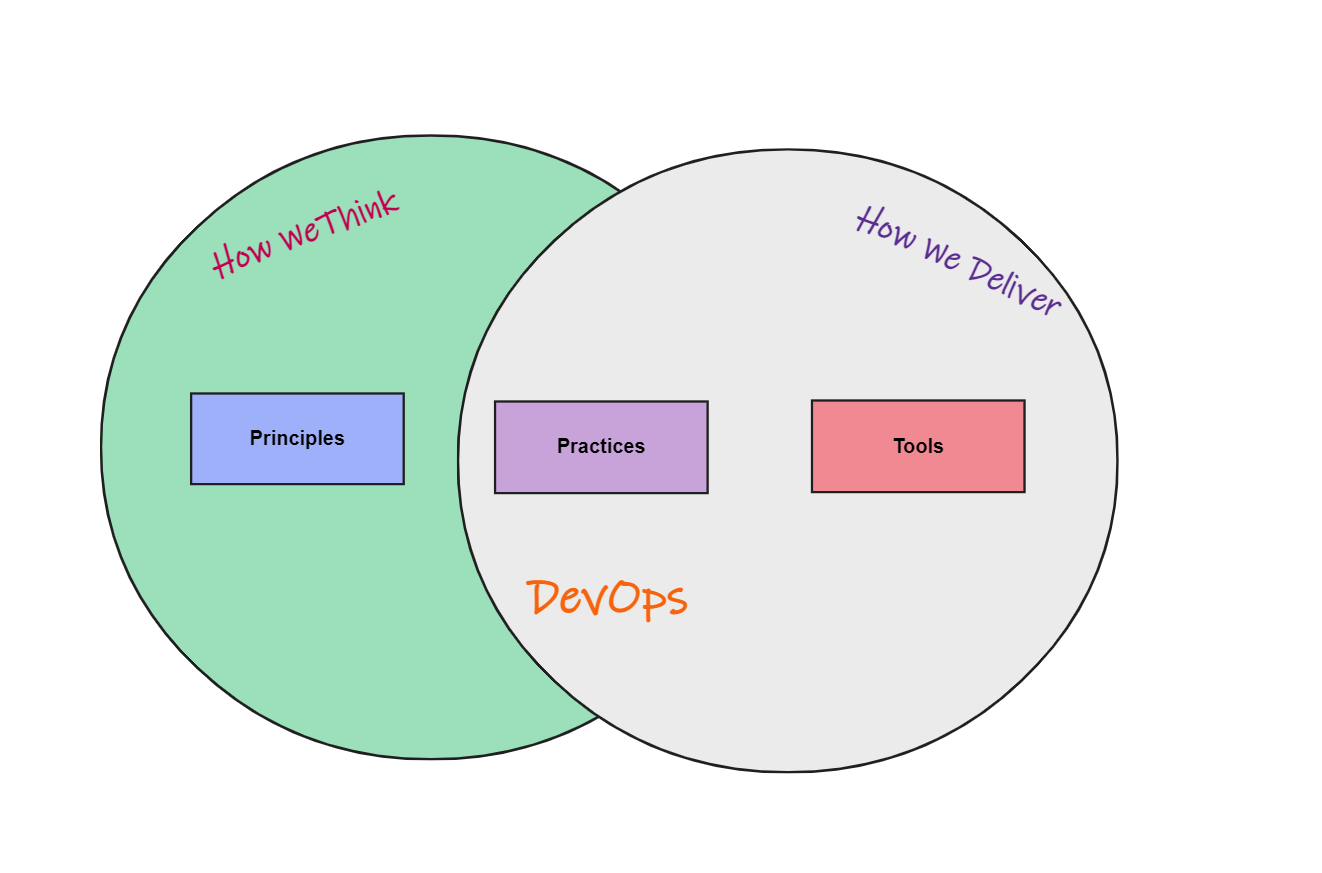
Tools are needed to automate and support these practices, so you'll find teams that embrace DevOps using tools that enable practices like frequent communication, CICD, and containerization.
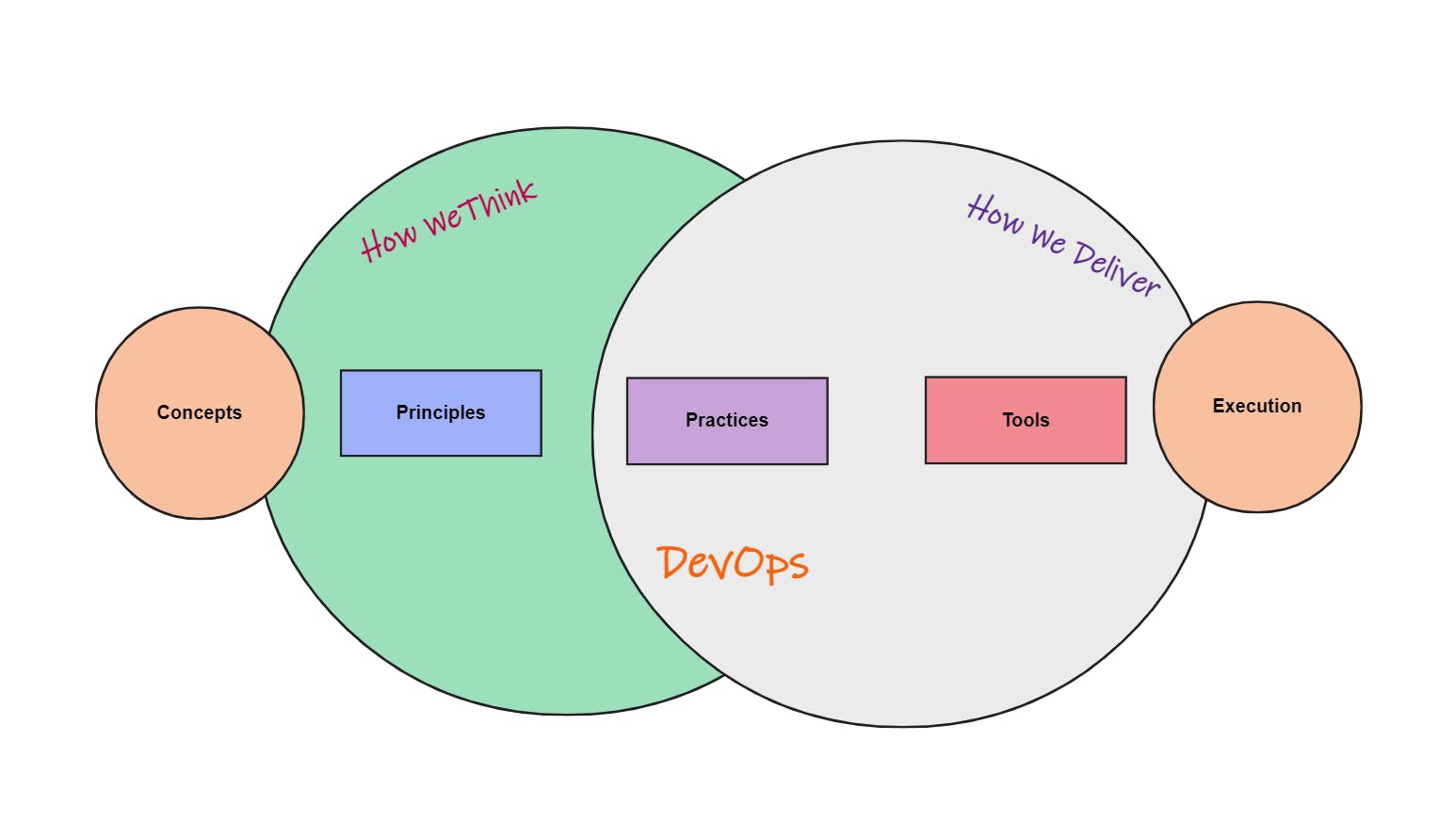
So you kind of get these two sides of DevOps, the concepts and the execution.
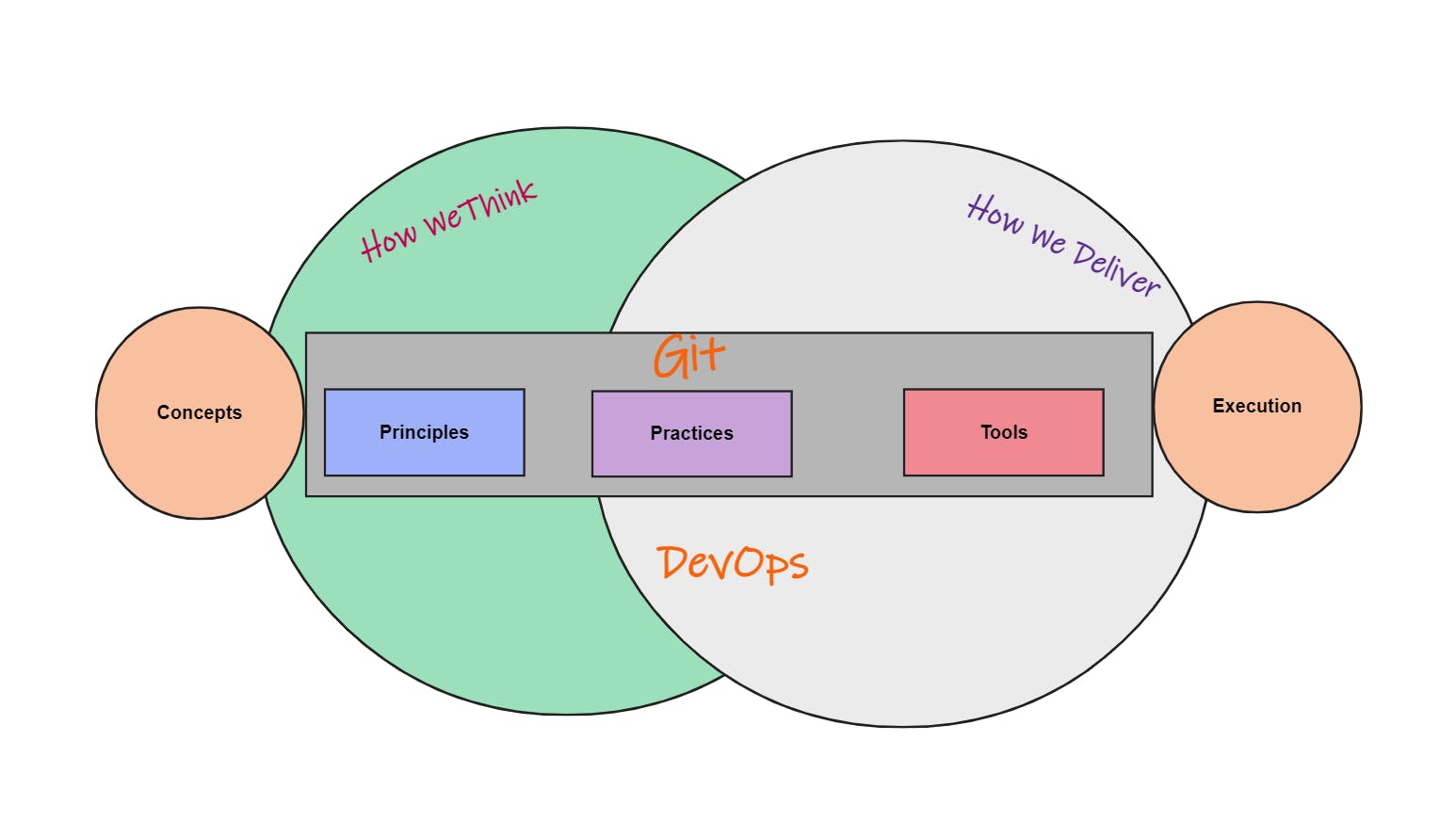
So what about GitOps, right? GitOps applies a Git-centric approach on top of some common DevOps principles, practices, and tools. So we mix these principles centered around Git in with our DevOps workflows to get this new way of operating and managing software.
The Big Idea
The principles established by the GitOps community stem from the idea that all system changes are made through source control, like Git, and from there, they're automatically deployed. Developers have been doing this forever, however, GitOps shifts this practice to the operations side, where infrastructure configuration is stored as code.
So you wind up with all your system changes described in Git as commits, and those commits in their entirety make up the desired state of your system.
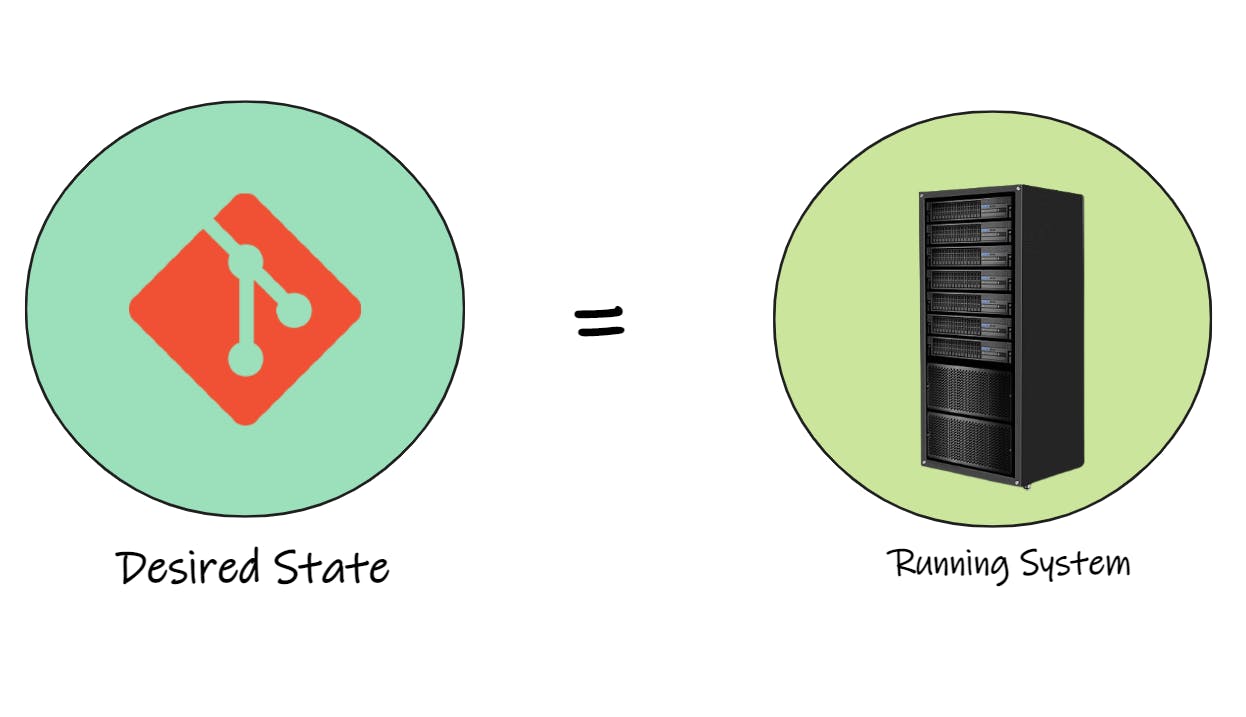
That desired state then needs to be reflected in your running system, which is done via a GitOps concept known as a control or a reconciliation loop.
But that's the core of GitOps. Commit all of your systems desired changes into Git, and that's what runs on your system.
There's more to it than that. You have the principles which are generally agreed upon. However, the practices can vary differently across groups and in some cases they're tough to put in place.
Evolution of GitOps
Evolution to GitOps helps to understand the history behind GitOps and the direction where it's heading.
The software development community is always searching for ways to deliver faster. Nobody likes waiting...., so it's pretty easy to convince management to support an idea that shortens the cycle.
The desire to move faster has driven several waves of evolution through our community in different spaces.
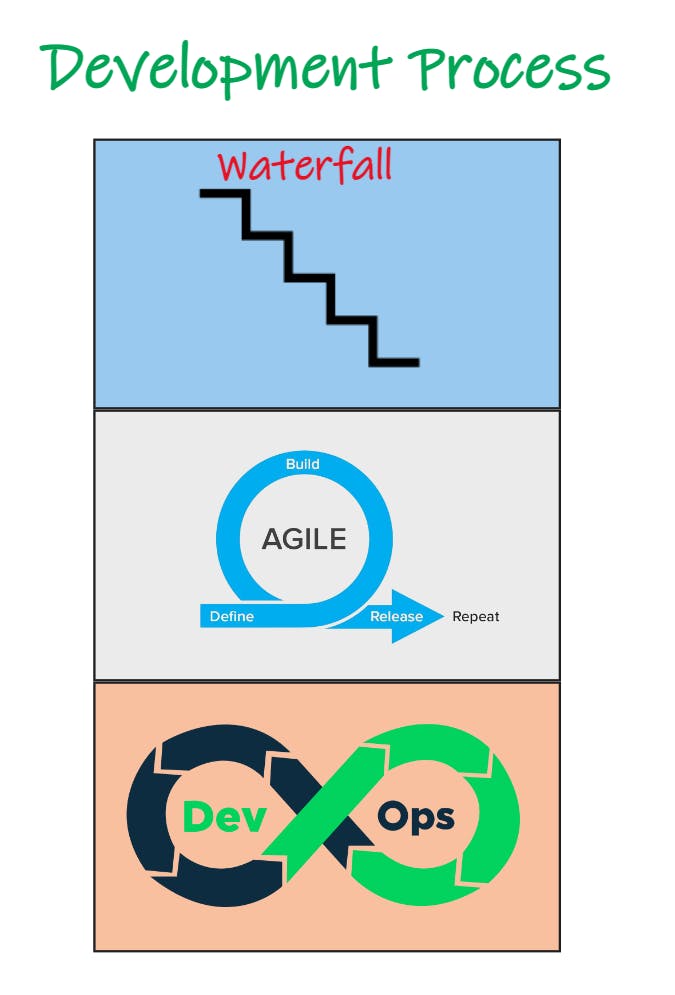
We've adopted more integrated development processes, leaving traditional waterfall methods behind for better ways of working, like Agile and DevOps, that will make teams more productive.
We've also broken systems down into fine-grain services so they're easier to change and deploy.
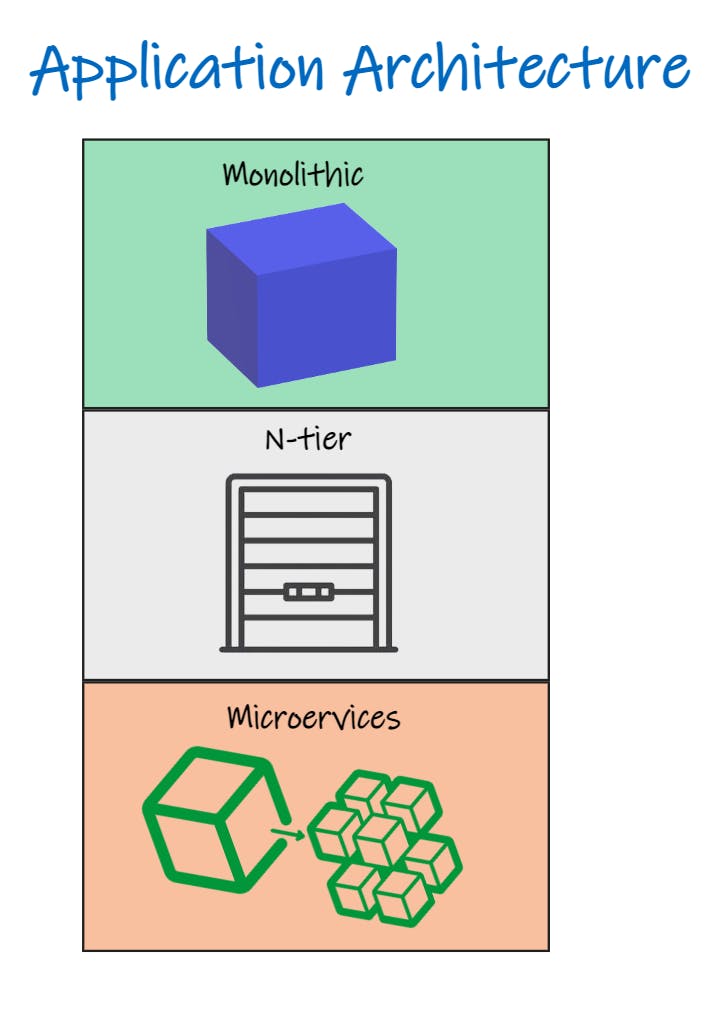
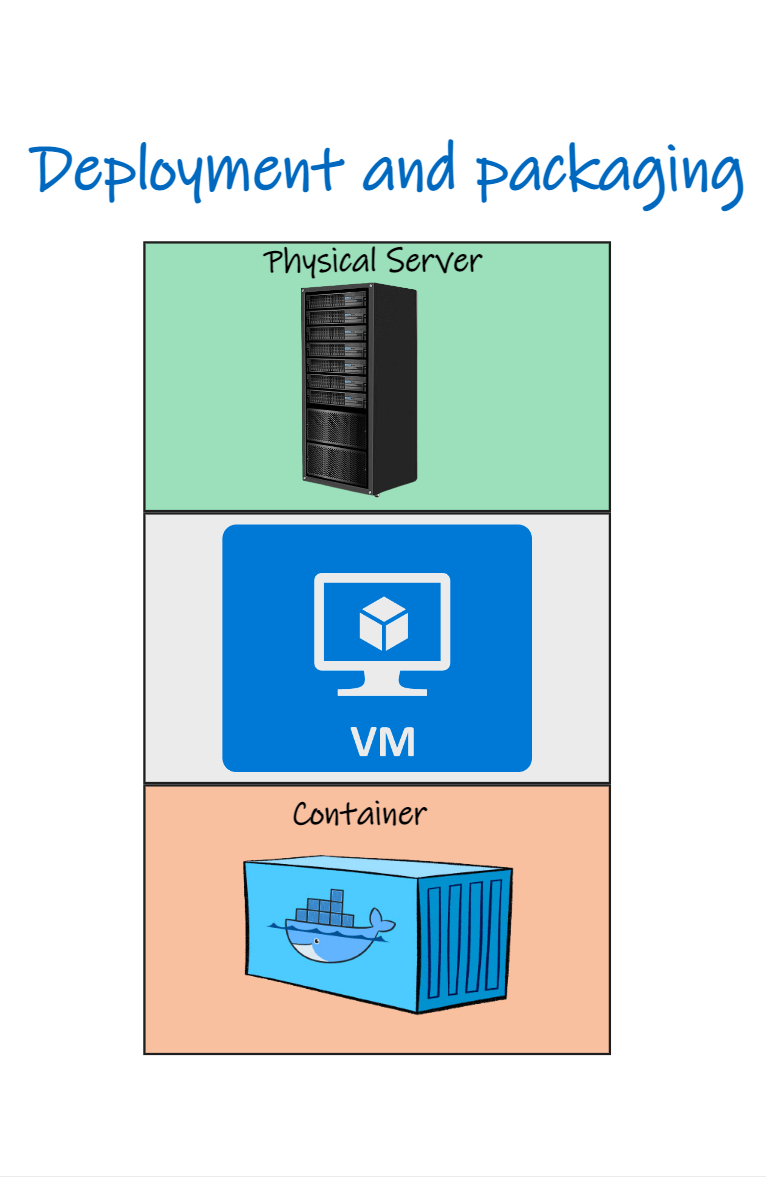
Apps have shifted from running on VMs to being packaged and deployed within immutable containers that scale quickly on orchestration platforms.
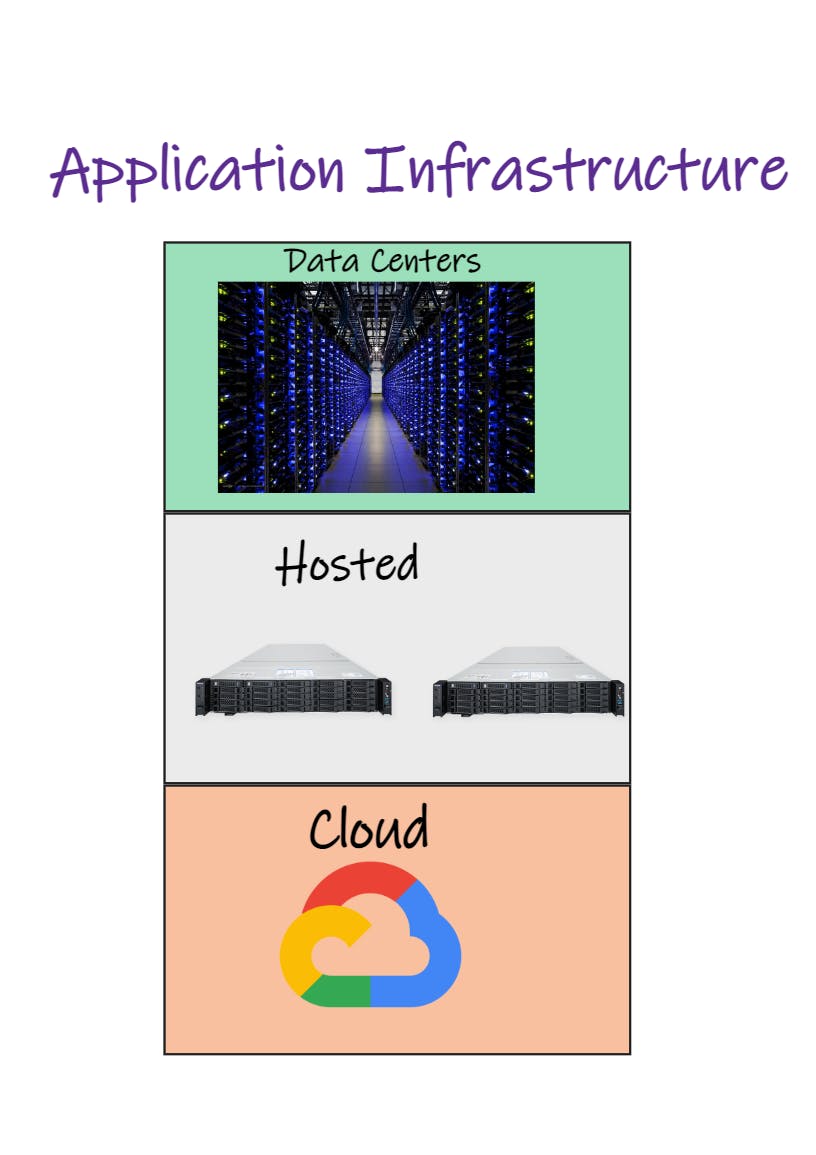
At the same time, we began shifting our infrastructure to the cloud, where platforms like Azure, GCP, and AWS have reduced provisioning times down from weeks to seconds.
Teams that progress through these stages often hit their goals for delivering faster, but there's unintended side effects. For example, systems will often become unstable if the operations side can't keep up with the increased rate change.

That's where GitOps enters the picture.
It focuses primarily on the operations, or Ops side. Using GitOps, teams manage operations through declarative infrastructure code stored in Git.
Changes to the code are released through a delivery pipeline controlled by an automated agent that applies the changes to the system.
This workflow for continuous delivery allows teams to rapidly, yet safely, deliver changes without sacrificing system stability.
GitOps Maturity
The idea of storing all aspects of your system in Git and using the repository to drive automation has been around for years.
However, it wasn't until 2017 that Weaveworks CEO, Alexis Richardson, first introduced the term GitOps in a blog post titled Operations by Pull Request.
Currently, a working group within the Cloud Native Computing Foundation is building a GitOps manifesto that standardizes GitOps principles.
The group recently formed and has participation from notable names in tech like Weaveworks, Codefresh, and Microsoft.
So the GitOps principles have solidified, but the practices and tolling will constantly be evolving. Everyone agrees the GitOps pattern will heavily influence how we'll work and how tolls will be built in the future, but everybody has a slightly different idea of how that's going to be implemented.
So it's an exciting time to be involved with GitOps. The future is promising, which is why it's important to grasp the concepts in the early stages.
How GitOps works
We're going to take a look at the big picture to see how GitOps is used to manage changes, deployments and operations of a system.
So let's start at the top and break it down from there.
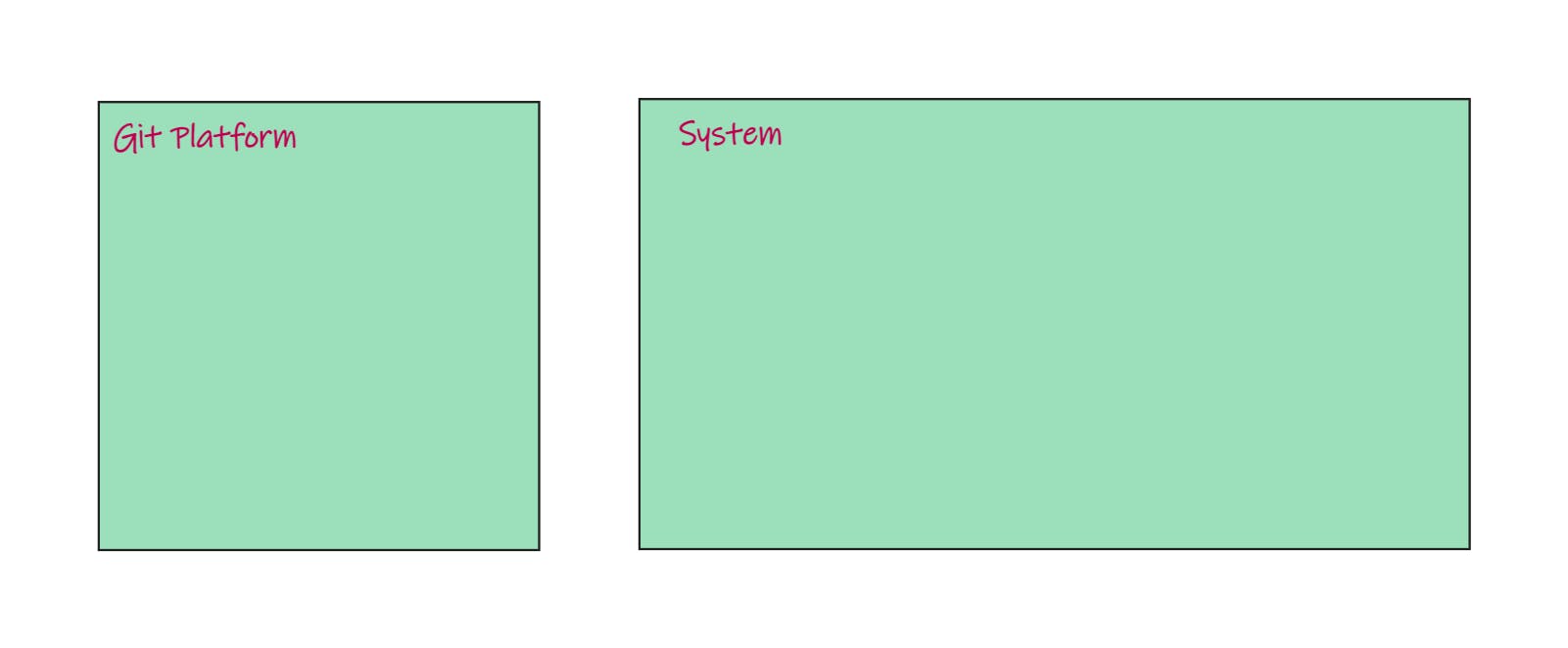
We have Git and we have our System.
Inside a Git, we store the desired state of our system.
State :- It is defined as the condition of something at a specific time. So right now, if you're happy and you're energetic, that's your current state, but with the system, state is more like how many nodes are in the cluster? What docker image am I running, or how many containers is it running in?
Okay, so that state in GitOps, we described system state using code, and it's always stored in Git through commits.
The code in Git is the single source of truth for the condition we want our system to be in.
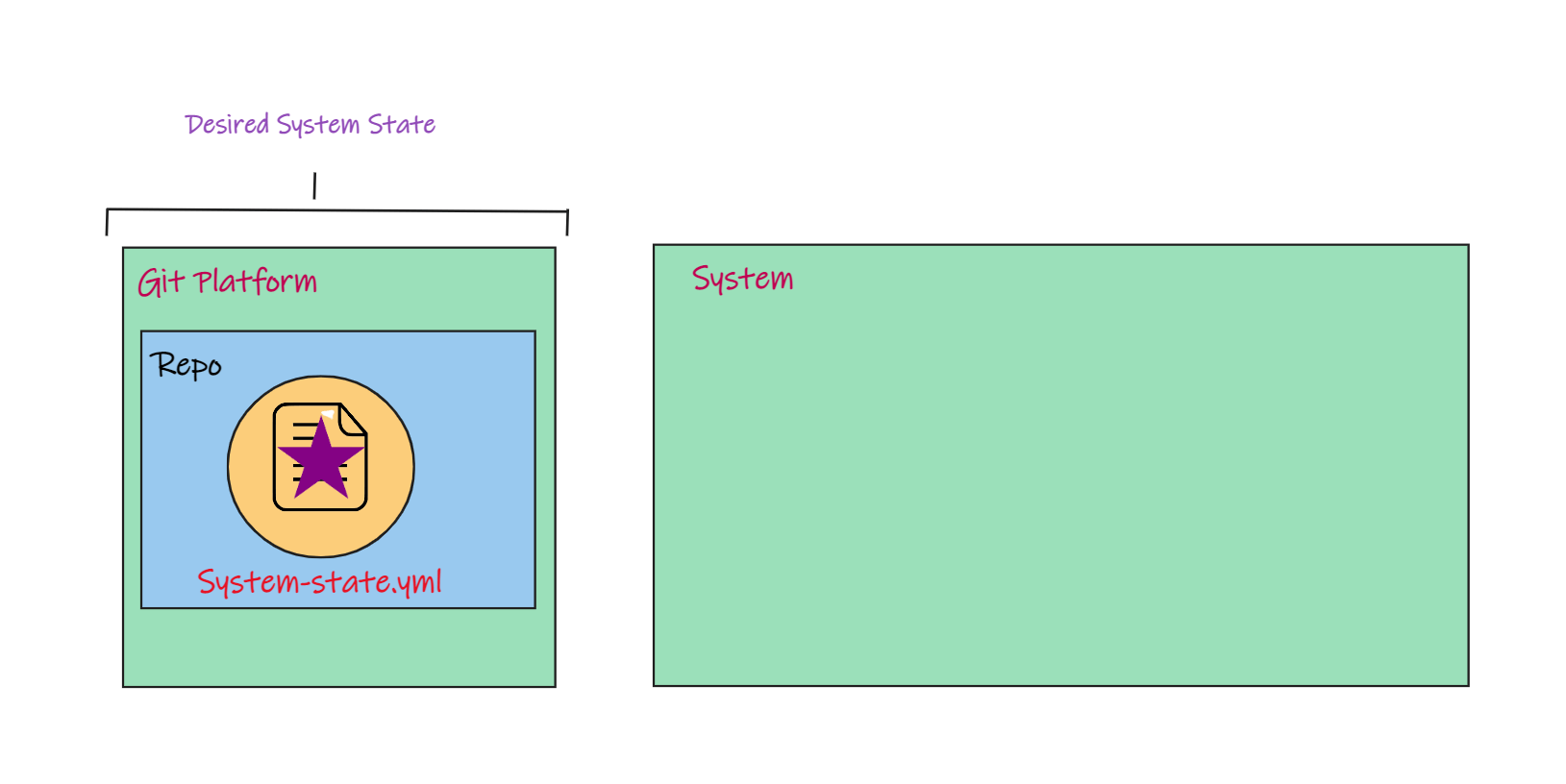
So here you can see, I committed an initial configuration file to my Git repository named system-state.yaml. That file says the system should run one purple star.
I'm just using shapes to keep it simple and to give you a visual. So the desired state says we need a purple star, but the current state of the system, its runtime state, doesn't match.
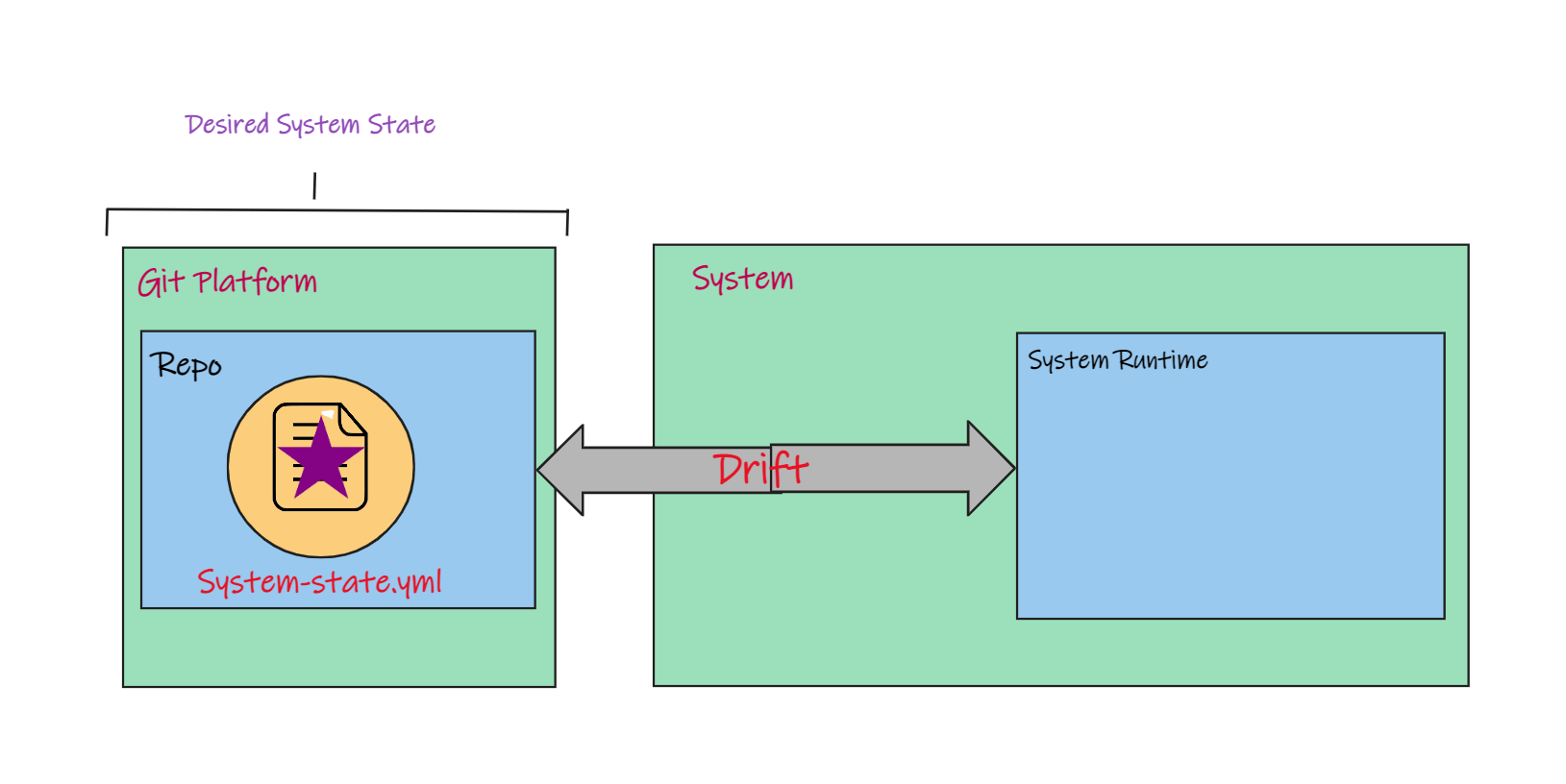
We have some drift between Git and the System because we haven't deployed our changes.
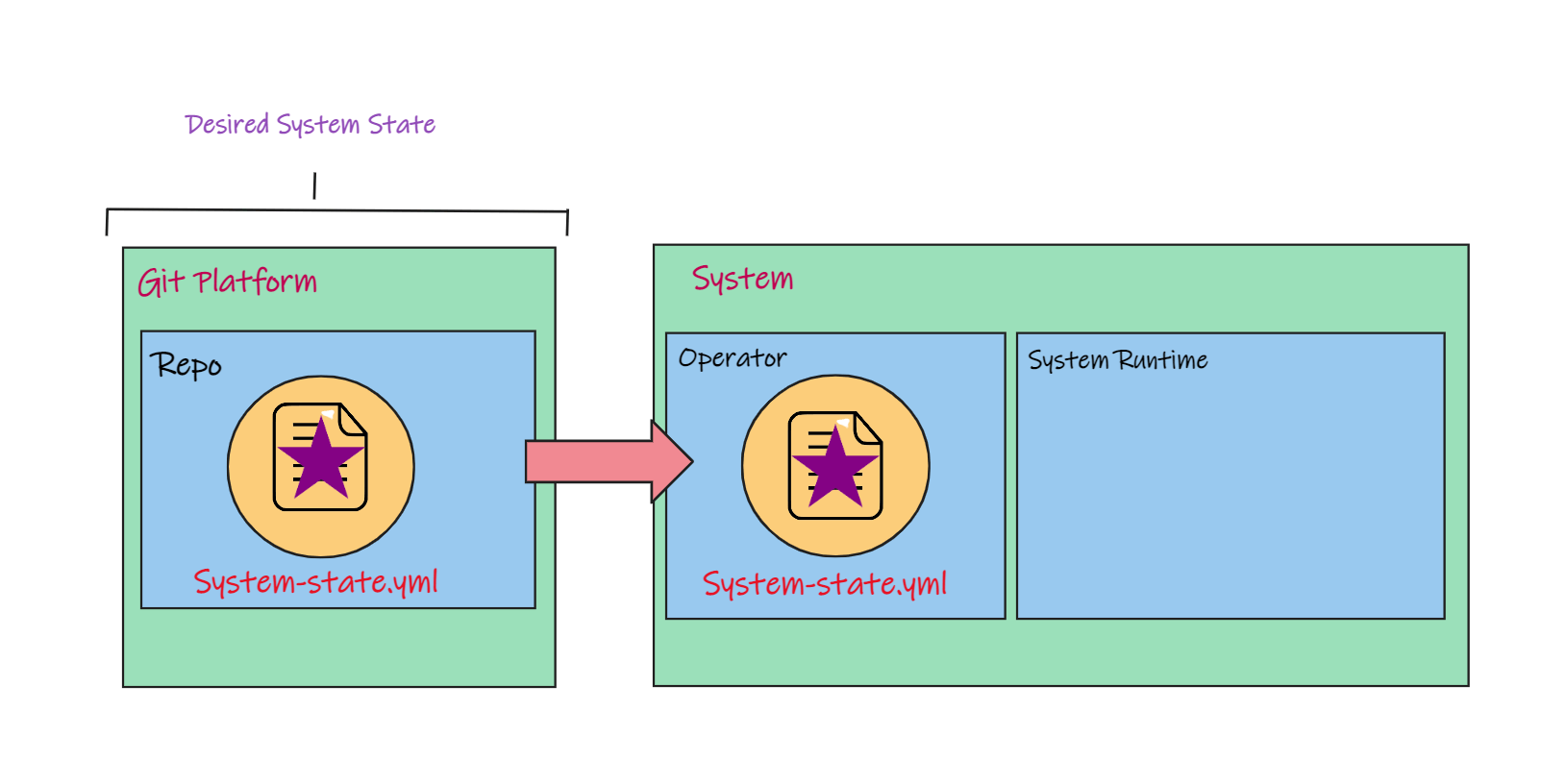
In GitOps, deployments are performed by an operator that runs inside the system.
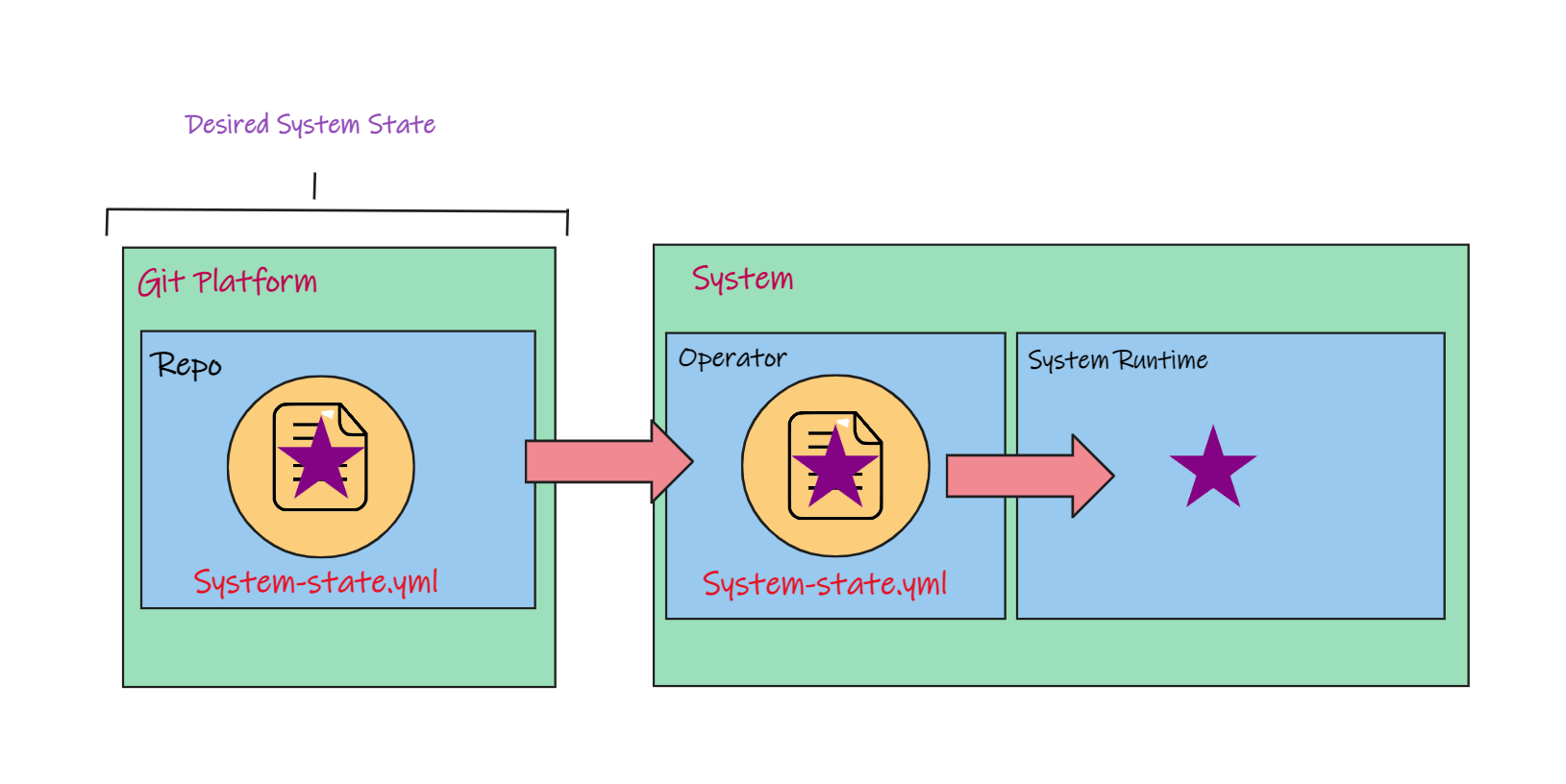
This operator will pull the code describing the desired system state from Git and then apply changes to the systems runtime to match the desired state.
That's exactly what we want, the desired state described in Git matches the runtime state of the system.
But let's say something happens in our system runtime drifts again.
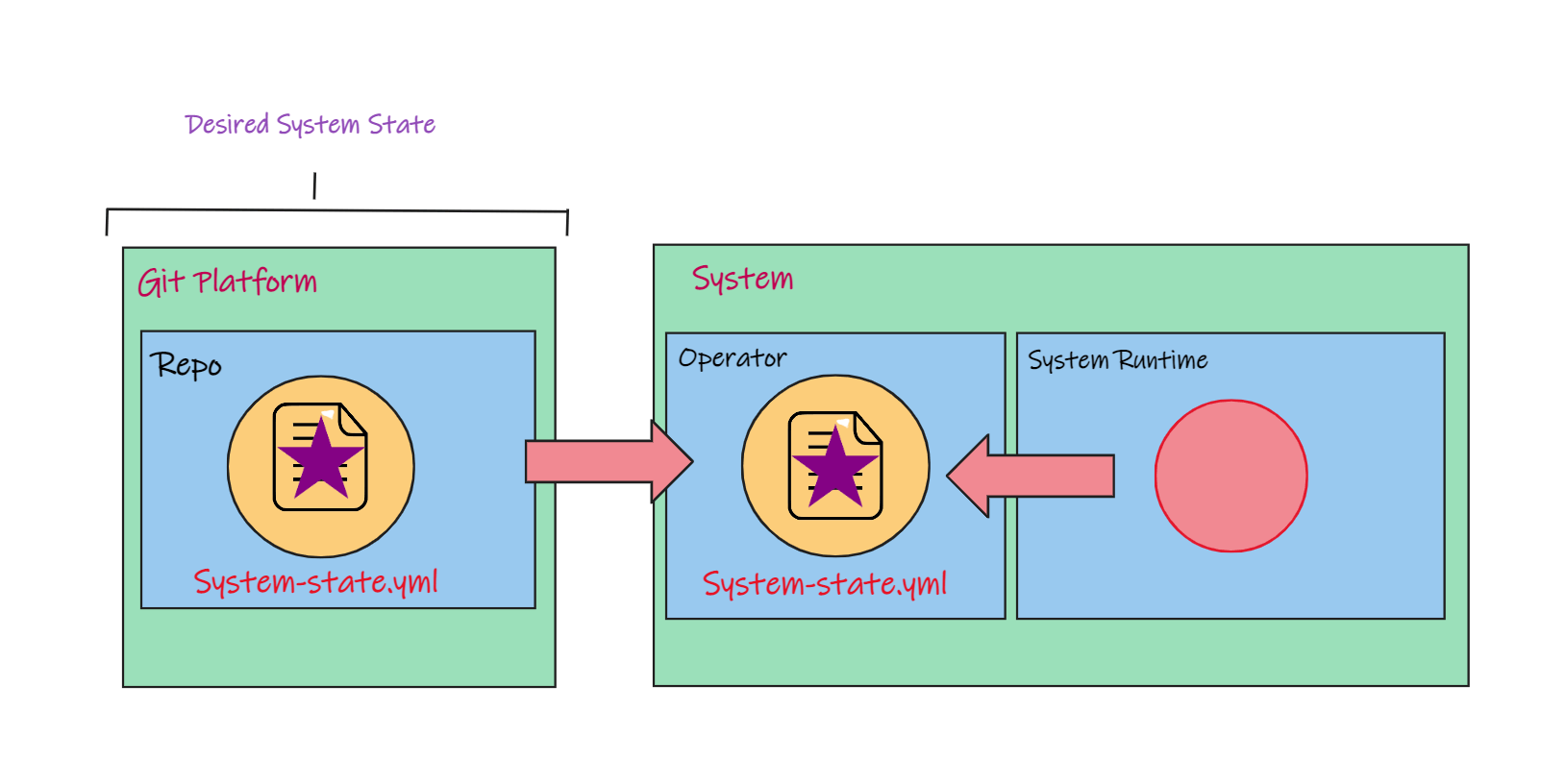
Instead of the purple star, we now have a red circle.
- In GitOps, we continually observe the system using the operator. So the operator notices the difference between the runtime state and the desired state, then it automatically corrects the drift between them.
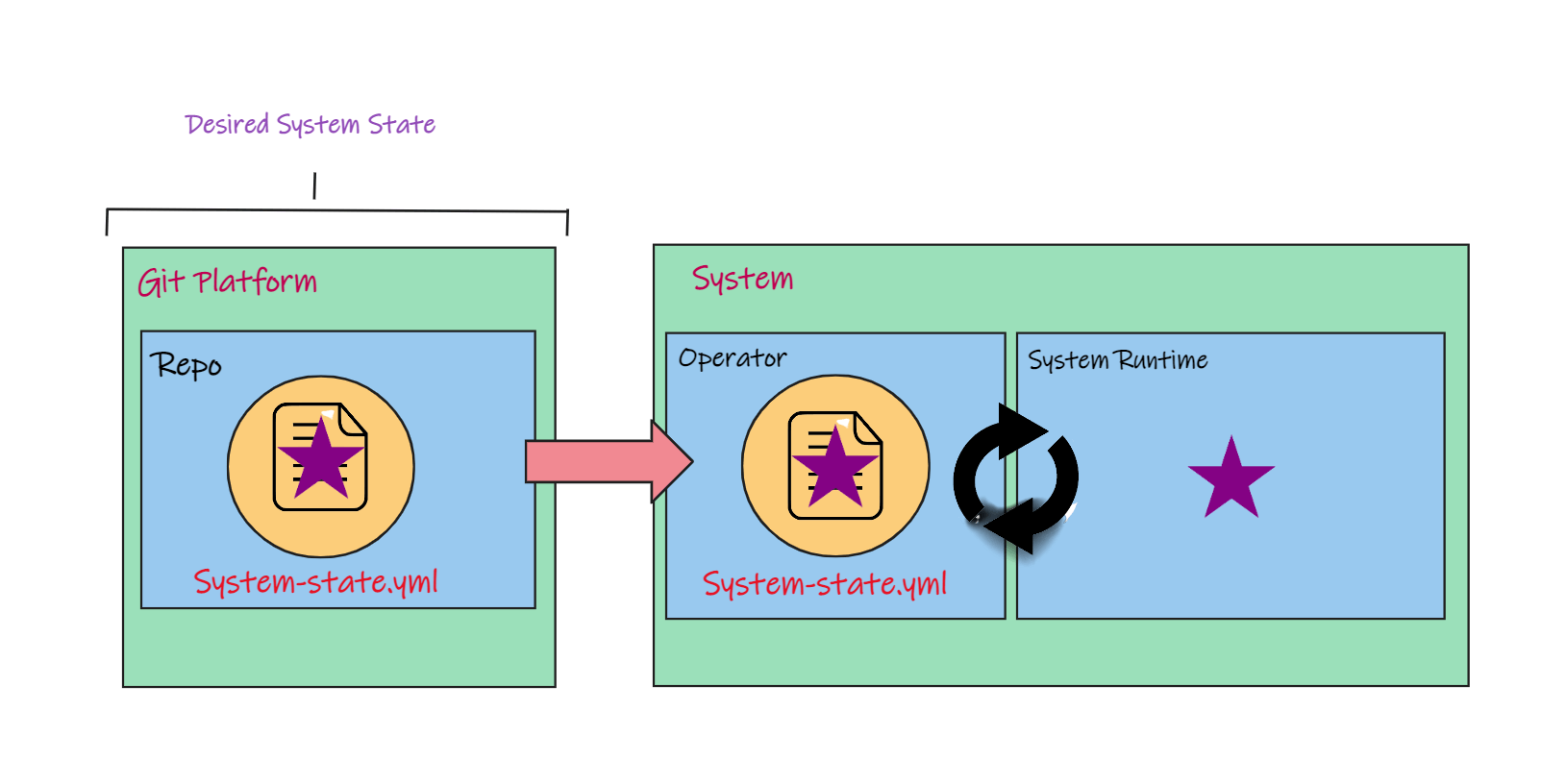
This monitoring and correction process that is continually running by the operator is known as the Control Loop or Reconciliation Loop.
Those are the general mechanics of how GitOps works.
- We store our systems desired state in Git,
- when that state changes we automate deployment of those changes so that our systems runtime state changes to match the desired state.
- If the runtime state ever deviates from the desired state, the control loop will align the runtime state back to the desired state.
GitOps Benefits
GitOps provides a number of benefits that improve how we manage and operate our systems.
Let's take a closer look at them.
Productivity
When you adopt a GitOps workflow, deploying a change starts with Git for every change every time.
Git becomes the only way for developers to make a change to the system.
Once developers make a commit, automation takes over to deploy the change to the running system.
So what's so great about that? Well, to deploy or release a change, a developer only needs to know a few Git commands.

Let me put it another way. If your delivery process looks like this, and it's understood only by about two people in your entire company, and somewhere in there is a secret handshake, GitOps can help.
It's automated and repeatable approach to continuous delivery allows anyone on the team to release changes. So releases start to occur more frequently, and the team delivers faster without compromising systems stability.
Stability
Because the GitOps pattern uses automation to deploy changes, the workflow is repeatable and consistent.
This makes system operations more predictable and less prone to human error, which causes your rate of successful deployments to increase.
If your system does experience an issue, all it takes is another Git commit that undoes the change to roll back the system to its last working state.
In the event of a complete meltdown, GitOps allows you to quickly rebuild the entire system using the declarative infrastructure code that is stored in Git that describes the entire system.
The bottom line is GitOps standardizes operational processes to remove risk and to avoid surprises.
Transparency
With GitOps, operations become transparent, because Git is the only way to make a change to the system. And it's where the entire system is described.
Silos between DevSecOps can be broken down using Git as a collaboration tool. With Git, team members can review, discuss, and approve the changes to the system that are being made using a pull request.
Anyone or anything with access can inspect the code. This includes automated tools that enforce security practices.
Security
GitOps provides a balance between strong security controls and the transparency that developers need to do their job.
Because the work and discussion around changes is centralized in Git, the workflow naturally builds an audit log.
You get traceability of who made or approved each change, which can be really important if you're working in a highly regulated environment.
Arguably, the most important security benefit of GitOps is that changes to the runtime state of the system are only applied by agents running in the system.
The need for external access to the system through tolls like SSH is eliminated. And it restricts how we make changes to a single method.
So, these are some of the high level benefits that draw organizations to a GitOps approach.
Next, we'll start to unpack the underlying GitOps principles. So you are rock solid on the core GitOps concepts.
GitOps Principles
If we think of GitOps as a pattern, there are four principles that make up that pattern.
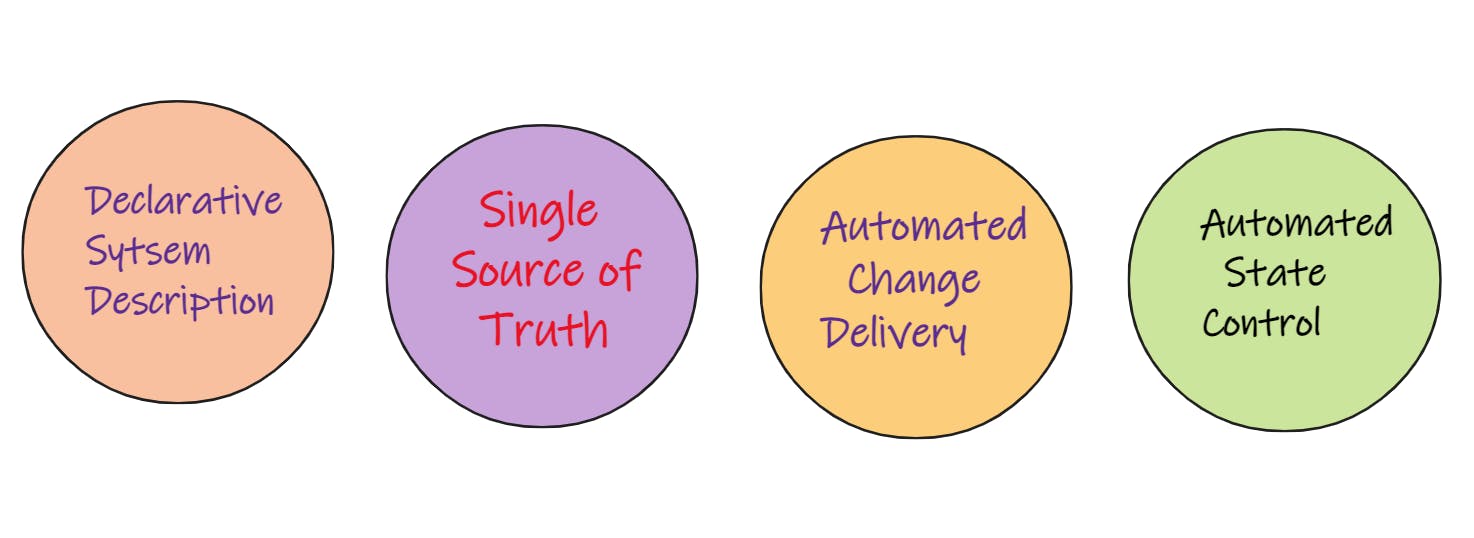
Let's take a look at them as a group, and then we'll dive into each one to see what they're all about.
Declarative System Description
The first principle requires us to describe our system declaratively. So we store data that describes the desired state of the system, sort of like a blueprint.
Single Source of Truth
The second principle requires that we store that description of our system within Git. So we agree to keep the official blueprints, describing the desired system state version within Git. If we want to change the blueprint, it has to be done via a git commit.
Automated Change Delivery
When we change the blueprint, the changes can only be applied to the running system through automation. Changed delivery is 100% automated. There are no manual changes in GitOps.
Automated State Control
The final principle ensures that our running system stays aligned to the desired state through automation. So if the running system drifts away from what we have described in Git, an operator within the system will heal it by returning it back to the desired state.
So that's great from a high level, but you have to be asking, how does it really work?
So let's invest some time in exploring each of these principles, then you'll know how to recognize the pattern when it appears in a workflow or toll that you use in your day to day work.
Declarative Configuration
The principle states that we should have a declarative description of the entire system.
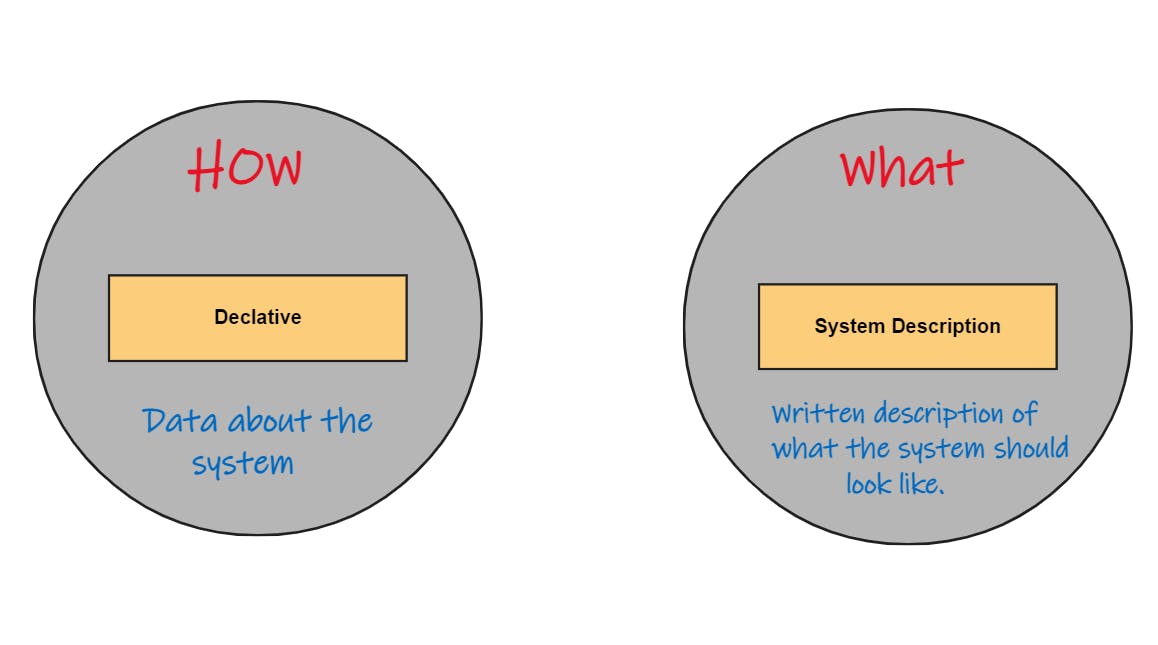
Let's start with the system description.
System Description is what is committed inside your Git repository. The system description will include one or more files that will define each system components and its state.
GitOps says how we store those definitions is important and we need to do it declaratively. That means our system description is going to be stored as data.
That's a little abstract but it's really the key to all this.
When managing infrastructure, the two major approaches are imperative and declarative.
Imperative Approach :-
It focuses on how we reach a desired state.
To do this, it assumes we execute a sequence of commands that change our system.
The imperative approach typically involves a CLI or a GUI console.
Declarative Approach :- The declarative approach taken by GitOps, flips this model.
Instead of specifying how, we just specify what we want the system to look like using a number of declarations that make up its description.
In the declarative approach, If we want to change the system, we update the description. We do not execute a series of commands.
Here's a trick to keep the two straight. Think of the imperative approach as a set of instructions that come with the piece of furniture that you assemble at home. It says step-by-step how to put it together. The declarative approach, is more like blueprints for a house. It describes the rooms, their dimensions, and features. It describes what to build not how to build it.
Let's look at both approaches using Kubernetes.
So assume we have a Kubernetes cluster running and on this cluster, we're going to create a deployment.
- We'll first do that imperatively.
So we're going to use kubectl, we'll create a deployment named imperative-deploy. And this deployment is going to launch an NGINX container on the cluster.
kubectl create deployment imperative-deploy --image=nginx
Now, let's talk about this. There's no visibility of my work and we cannot reproduce those commands that I just issued.
- Now let's contrast that with the declarative approach.
For this approach, we have described the Kubernetes objects in a declarative YAML file named deployment.yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Notice how the file describes what the system should look like.
You can read this and know the state of what the system should be.
If I wanted to make a change, let's say there's a new NGINX image available. I can go ahead and do that within the declarative configuration not by executing a command.
Now, of course the change would need to be applied on the cluster and in GitOps, that's done through an agent, not kubectl.
But the point is, this would be stored in Git and all my teammates could see the change that I made to the system.
Declarative configuration is important for GitOps because it describes the system in a way that an automated agent can read and act upon.
The declarative description of our system becomes its desired state, which leads us to our next principle.
Git as the source of truth
Our next principle declares Git as the single source of truth for our system. As simple as that sounds, it's really important for GitOps.
Let's start with our blueprint analogy.
A blueprint represents the desired state of a house. It's what the homeowner, the builder, and the workers agree the house should look like when it's finished. If the blueprints do not have a bathroom, the house won't either. If you want to change the house by adding another room, the blueprints need to be updated so that everybody working on the house understands what needs to be built.
All right, let's tie that to GitOps.
In GitOps we store everything in Git. So inside of Git we'll find things like the application code, tests, image definitions, and our declared infrastructure configuration.
Now, I will highlight that GitOps is meant for operations, so it really focuses on the infrastructure code. But still, anything pertaining to the system is in Git. It has all the blueprints related to the system. We call this our desired state.
If something isn't in the desired state, AKA the blueprints, it shouldn't be in the system.
This makes Git the only place that developers, operations, security, and automations check when trying to determine what should be running in the system.
If changes to the system are necessary, a commit is the only way to update the blueprints in Git.
Having one place to store the description of our system's desired state has many advantages. At any point in time, anyone or anything can turn to Git as the single source of truth for the system.
This includes automated agents that observe the system's desired state while watching for any changes. Having Git as the single source of truth provides us with auditability. What changed, who changed it, and when the change happened is stored in Git, because every change to the system is described with a commit.
GitOps also increases a system's recoverability because we can easily revert a failed change or recover the entire system from the repository.
That about covers it. The main concepts behind this principle are simple. Put everything about your system in Git and manage it from there.
Automated Change Delivery
Let's cover the next GitOps principle, which requires changes to the system to be delivered with automation.
Okay, let's unpack that some.
We know git commits are the only way to change the system's blueprints or desired state.
In GitOps, once the commit occurs, deployment of the actual change is automated.
We've touched on this before. A commit is made against Git, the desired state is updated, then it's pulled into the system by an operator that applies the changes to the running system.
Once the blueprints are updated by the commit, all the work in GitOps to deploy the change is done with automation.
Now let's talk a little bit about what this principle doesn't allow for.
If we get a new idea for the system and directly make the change against it, we violate this principle because GitOps doesn't allow us to apply changes outside of the automated procedures.
So if you're familiar with SSHing into a box or running kubctl apply, you'll need to adjust and allow the automated agents to handle shipping your changes.
Giving up that access to adhere to this principle comes with benefits.
Automation allows changes to be delivered through standard workflows that are easier for developers to use because they only require Git and Git is such a well-known tool.
Automation also standardizes your delivery procedures, making system operations more consistent and predictable.
This principle also delivers huge security advantages because the automated agents run inside the system. This allows you to restrict access and limit the exposure of sensitive details of the system like management APIs, or credentials.
Automated state control
The final GitOps principle focuses on how we control the running system to ensure it remains in its desired state.
There are some thread between the GitOps principles.
For example, the first two principles primarily deal with creating and managing a desired state for the system. They relate to how we build the system blueprints that describe what it looks like.
The last two principles focus more on the runtime state of the system. They describe concepts that help ensure the running system matches the desired state.
We've seen how automated change delivery can apply updates to the system's runtime state, but once those changes are applied, how do we ensure the system stays that way?
When our system's runtime state deviates from its desired state, this is known as drift. There's a mismatch between the system's blueprints and what is actually running in the system.
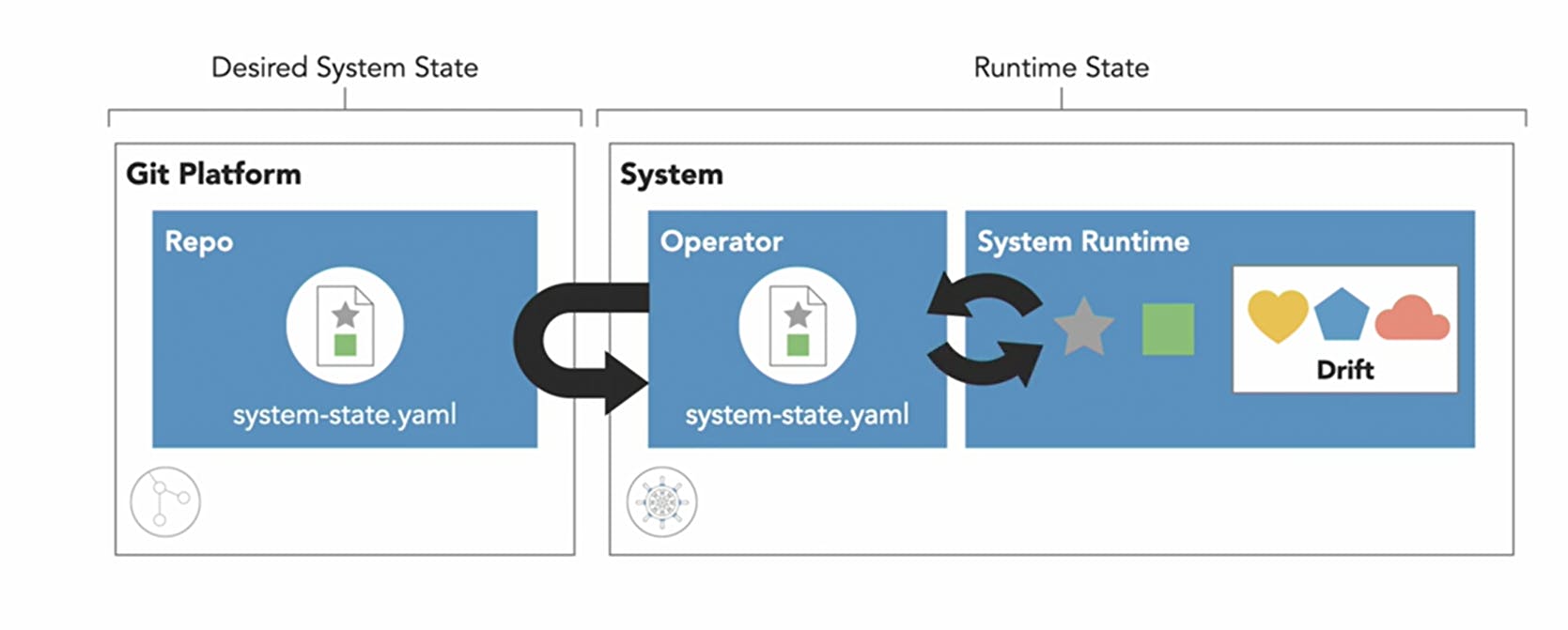
This is where the fourth GitOps principle automated state control comes into play.
Operators observe the desired system state, and they observe the running state of the system. After comparing the two, the operator begins to apply changes that reconcile the drift and converge the running state of the system back to its desired state.
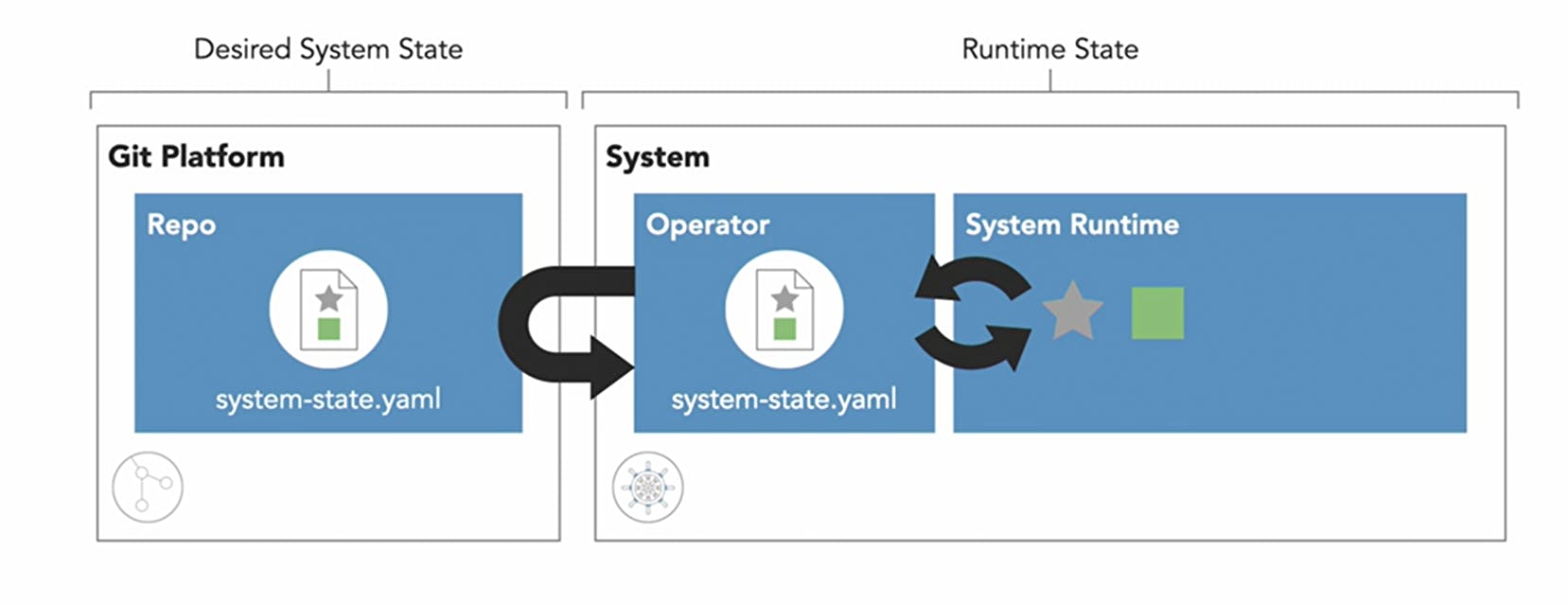
So the operator controls the runtime state by enforcing against changes that take the system away from its desired state.
It's easy to see the benefits here.
We establish a feedback loop to observe our system and automatically correct any deviations from the desired state.
It's as if a system admin were watching the system constantly. So you can go ahead and sleep through the night when things go awry.
So that covers the principles behind GitOps. You'll find these principles underlying the workflows, practices, and tools that use the GitOps pattern, which we'll see another blog.
Now That's about this Blog An introduction to GitOps Hope you liked it! 😊
Thank You for Reading 😊😊